In [2]:
%matplotlib inline
import tensorflow as tf
import numpy as np
import sys
import os
sys.path.insert(0, os.path.abspath(os.path.join("..", "..", "..")))
import pysgmcmc as pg
1. Instantiating a Sampler¶
To instantiate a sampler, we need two ingredients:
- Target parameters of the sampler: a list of
tensorflow.Variableobjects - A cost function: callable that maps these target parameters to a 1-d
tensorflow.Tensorrepresenting their corresponding costs
Note: In MCMC literature, the target parameters are often denoted as \(\theta\). Our cost function corresponds to the negative of the log likelihood. The log likelihood is frequently referred to as \(U(\theta)\) in literature, so our cost function corresponds to \(-U(\theta)\).
In [2]:
# target parameters
parameters = [tf.Variable(0.), tf.Variable(0.)]
# cost function
def banana_nll(params):
x, y = params
return -1./2. * (x ** 2 / 100. + (y + 0.1 * x ** 2 -10) ** 2)
Given these ingredients, we can instantiate any of our samplers within a
tensorflow.Session:
In [3]:
from pysgmcmc.samplers.sghmc import SGHMCSampler
session = tf.Session()
sampler = SGHMCSampler(
params=parameters, cost_fun=banana_nll, session=session, dtype=tf.float32
)
session.run(tf.global_variables_initializer()) # initialize variables
Using data minibatches¶
A major motivation to use Stochastic Gradient MCMC methods is that they leverage MCMC methods to large datasets by subsampling them.
To this end, our samplers take an iterable batch_generator as input and use it to repeatedly subsample the dataset.
We provide two simple default ways to generate batches, which can be found in module pysgmcmc.data_batches. You can easily add your own custom batch generation facilities, e.g. by writing a (infinite) generator function that yields a dictionary mapping two placeholders for the data to batches of data (usually np.arrays).
In [4]:
from pysgmcmc.samplers.sghmc import SGHMCSampler
from pysgmcmc.data_batches import generate_batches
session = tf.Session()
params = [tf.Variable(0., dtype=tf.float64)]
def sinc(x):
import numpy as np
return np.sinc(x * 10 - 5).sum(axis=1)
# XXX: Use cost function from BNN Negloglikelihood here?
# Then, we can even show a batch and run a single iteration
dummy_costs = lambda params: tf.reduce_sum(params) # dummy cost function; ignore this it is not used
## Set up data ##
rng, n_datapoints = np.random.RandomState(np.random.randint(0, 10000)), 100
X = np.array([rng.uniform(0., 1., 1) for _ in range(n_datapoints)])
y = sinc(X)
x_placeholder, y_placeholder = tf.placeholder(dtype=tf.float64), tf.placeholder(dtype=tf.float64)
## Batch Generator (uniform random subsampling) ##
batch_generator = generate_batches(X, y, x_placeholder, y_placeholder, batch_size=20)
batched_sampler = SGHMCSampler(
params=params, cost_fun=dummy_costs, session=session,
batch_generator=batch_generator # Pass the iterable into our sampler
)
All calls to
next(batched_sampler)
will use batches obtained by calling next(batch_generator) when
computing the costs for the current iteration.
Note: the cost function (cost_fun) passed to the sampler must use
the placeholders passed to generate_batches.
Available samplers¶
To get an overview of which samplers are available for use, examine our documentation or simply run:
In [5]:
help(pg.samplers)
Help on package pysgmcmc.samplers in pysgmcmc:
NAME
pysgmcmc.samplers
PACKAGE CONTENTS
base_classes
relativistic_sghmc
sghmc
sgld
sgnuts
svgd
CLASSES
pysgmcmc.samplers.base_classes.BurnInMCMCSampler(pysgmcmc.samplers.base_classes.MCMCSampler)
pysgmcmc.samplers.sghmc.SGHMCSampler
pysgmcmc.samplers.sgld.SGLDSampler
pysgmcmc.samplers.base_classes.MCMCSampler(builtins.object)
pysgmcmc.samplers.relativistic_sghmc.RelativisticSGHMCSampler
pysgmcmc.samplers.svgd.SVGDSampler
class RelativisticSGHMCSampler(pysgmcmc.samplers.base_classes.MCMCSampler)
| Relativistic Stochastic Gradient Hamiltonian Monte-Carlo Sampler.
|
| See [1] for more details on Relativistic SGHMC.
|
| [1] X. Lu, V. Perrone, L. Hasenclever, Y. W. Teh, S. J. Vollmer
| In Proceedings of the 20 th International Conference on Artificial Intelligence and Statistics (AISTATS) 2017
|
| `Relativistic Monte Carlo <http://proceedings.mlr.press/v54/lu17b/lu17b.pdf>`_
|
| Method resolution order:
| RelativisticSGHMCSampler
| pysgmcmc.samplers.base_classes.MCMCSampler
| builtins.object
|
| Methods defined here:
|
| __init__(self, params, cost_fun, batch_generator=None, stepsize_schedule=<pysgmcmc.stepsize_schedules.ConstantStepsizeSchedule object at 0x7f09872bf0b8>, mass=1.0, speed_of_light=1.0, D=1.0, Bhat=0.0, session=None, dtype=tf.float64, seed=None)
| Initialize the sampler parameters and set up a tensorflow.Graph
| for later queries.
|
| Parameters
| ----------
| params : list of tensorflow.Variable objects
| Target parameters for which we want to sample new values.
|
| Cost : tensorflow.Tensor
| 1-d Cost tensor that depends on `params`.
| Frequently denoted as U(theta) in literature.
|
| batch_generator : BatchGenerator, optional
| Iterable which returns dictionaries to feed into
| tensorflow.Session.run() calls to evaluate the cost function.
| Defaults to `None` which indicates that no batches shall be fed.
|
| stepsize_schedule : pysgmcmc.stepsize_schedules.StepsizeSchedule
| Iterator class that produces a stream of stepsize values that
| we can use in our samplers.
| See also: `pysgmcmc.stepsize_schedules`
|
| mass : float, optional
| mass constant.
| Defaults to `1.0`.
|
| speed_of_light : float, optional
| "Speed of light" constant. TODO EXTEND DOKU
| Defaults to `1.0`.
|
| D : float, optional
| Diffusion constant.
| Defaults to `1.0`.
|
| Bhat : float, optional
| TODO: Documentation
|
| session : tensorflow.Session, optional
| Session object which knows about the external part of the graph
| (which defines `Cost`, and possibly batches).
| Used internally to evaluate (burn-in/sample) the sampler.
|
| dtype : tensorflow.DType, optional
| Type of elements of `tensorflow.Tensor` objects used in this sampler.
| Defaults to `tensorflow.float64`.
|
| seed : int, optional
| Random seed to use.
| Defaults to `None`.
|
| See Also
| ----------
| pysgmcmc.sampling.MCMCSampler:
| Base class for `RelativisticSGHMCSampler` that specifies how
| actual sampling is performed (using iterator protocol,
| e.g. `next(sampler)`).
|
| ----------------------------------------------------------------------
| Methods inherited from pysgmcmc.samplers.base_classes.MCMCSampler:
|
| __iter__(self)
| Allows using samplers as iterators.
|
| Examples
| ----------
| Extract the first three thousand samples (with costs) from a sampler:
|
| >>> import tensorflow as tf
| >>> import numpy as np
| >>> from itertools import islice
| >>> from pysgmcmc.samplers.sghmc import SGHMCSampler
| >>> session = tf.Session()
| >>> x = tf.Variable(1.0)
| >>> dist = tf.contrib.distributions.Normal(loc=0., scale=1.)
| >>> n_burn_in, n_samples = 1000, 2000
| >>> sampler = SGHMCSampler(params=[x], burn_in_steps=n_burn_in, cost_fun=lambda x: -dist.log_prob(x), session=session, dtype=tf.float32)
| >>> session.run(tf.global_variables_initializer())
| >>> burn_in_samples = list(islice(sampler, n_burn_in)) # perform all burn_in steps
| >>> samples = list(islice(sampler, n_samples))
| >>> len(burn_in_samples), len(samples)
| (1000, 2000)
| >>> session.close()
| >>> tf.reset_default_graph() # to avoid polluting test environment
|
| __next__(self, feed_dict=None)
| Compute and return the next sample and
| next cost values for this sampler.
|
| Returns
| --------
| sample: list of numpy.ndarray objects
| Sampled values are a `numpy.ndarray` for each target parameter.
|
| cost: numpy.ndarray (1,)
| Current cost value of the last evaluated target parameter values.
|
| Examples
| --------
| Extract the next sample (with costs) from a sampler:
|
| >>> import tensorflow as tf
| >>> import numpy as np
| >>> from itertools import islice
| >>> from pysgmcmc.samplers.sghmc import SGHMCSampler
| >>> session = tf.Session()
| >>> x = tf.Variable(1.0)
| >>> dist = tf.contrib.distributions.Normal(loc=0., scale=1.)
| >>> n_burn_in = 1000
| >>> sampler = SGHMCSampler(params=[x], burn_in_steps=n_burn_in, cost_fun=lambda x:-dist.log_prob(x), session=session, dtype=tf.float32)
| >>> session.run(tf.global_variables_initializer())
| >>> sample, cost = next(sampler)
| >>> session.close()
| >>> tf.reset_default_graph() # to avoid polluting test environment
|
| ----------------------------------------------------------------------
| Data descriptors inherited from pysgmcmc.samplers.base_classes.MCMCSampler:
|
| __dict__
| dictionary for instance variables (if defined)
|
| __weakref__
| list of weak references to the object (if defined)
|
| ----------------------------------------------------------------------
| Data and other attributes inherited from pysgmcmc.samplers.base_classes.MCMCSampler:
|
| __metaclass__ = <class 'abc.ABCMeta'>
| Metaclass for defining Abstract Base Classes (ABCs).
|
| Use this metaclass to create an ABC. An ABC can be subclassed
| directly, and then acts as a mix-in class. You can also register
| unrelated concrete classes (even built-in classes) and unrelated
| ABCs as 'virtual subclasses' -- these and their descendants will
| be considered subclasses of the registering ABC by the built-in
| issubclass() function, but the registering ABC won't show up in
| their MRO (Method Resolution Order) nor will method
| implementations defined by the registering ABC be callable (not
| even via super()).
class SGHMCSampler(pysgmcmc.samplers.base_classes.BurnInMCMCSampler)
| Stochastic Gradient Hamiltonian Monte-Carlo Sampler that uses a burn-in
| procedure to adapt its own hyperparameters during the initial stages
| of sampling.
|
| See [1] for more details on this burn-in procedure.
|
| See [2] for more details on Stochastic Gradient Hamiltonian Monte-Carlo.
|
| [1] J. T. Springenberg, A. Klein, S. Falkner, F. Hutter
| In Advances in Neural Information Processing Systems 29 (2016).
|
|
| `Bayesian Optimization with Robust Bayesian Neural Networks. <http://aad.informatik.uni-freiburg.de/papers/16-NIPS-BOHamiANN.pdf>`_
|
|
| [2] T. Chen, E. B. Fox, C. Guestrin
| In Proceedings of Machine Learning Research 32 (2014).
|
| `Stochastic Gradient Hamiltonian Monte Carlo <https://arxiv.org/pdf/1402.4102.pdf>`_
|
| Method resolution order:
| SGHMCSampler
| pysgmcmc.samplers.base_classes.BurnInMCMCSampler
| pysgmcmc.samplers.base_classes.MCMCSampler
| builtins.object
|
| Methods defined here:
|
| __init__(self, params, cost_fun, batch_generator=None, stepsize_schedule=<pysgmcmc.stepsize_schedules.ConstantStepsizeSchedule object at 0x7f09508b53c8>, burn_in_steps=3000, mdecay=0.05, scale_grad=1.0, session=None, dtype=tf.float64, seed=None)
| Initialize the sampler parameters and set up a tensorflow.Graph
| for later queries.
|
| Parameters
| ----------
| params : list of tensorflow.Variable objects
| Target parameters for which we want to sample new values.
|
| cost_fun : callable
| Function that takes `params` as input and returns a
| 1-d `tensorflow.Tensor` that contains the cost-value.
| Frequently denoted with `U` in literature.
|
| batch_generator : iterable, optional
| Iterable which returns dictionaries to feed into
| tensorflow.Session.run() calls to evaluate the cost function.
| Defaults to `None` which indicates that no batches shall be fed.
|
| stepsize_schedule : pysgmcmc.stepsize_schedules.StepsizeSchedule
| Iterator class that produces a stream of stepsize values that
| we can use in our samplers.
| See also: `pysgmcmc.stepsize_schedules`
|
| burn_in_steps : int, optional
| Number of burn-in steps to perform. In each burn-in step, this
| sampler will adapt its own internal parameters to decrease its error.
| Defaults to `3000`.
|
| For reference see:
| `Bayesian Optimization with Robust Bayesian Neural Networks. <http://aad.informatik.uni-freiburg.de/papers/16-NIPS-BOHamiANN.pdf>`_
|
| mdecay : float, optional
| (Constant) momentum decay per time-step.
| Defaults to `0.05`.
|
| For reference see:
| `Bayesian Optimization with Robust Bayesian Neural Networks. <http://aad.informatik.uni-freiburg.de/papers/16-NIPS-BOHamiANN.pdf>`_
|
| scale_grad : float, optional
| Value that is used to scale the magnitude of the noise used
| during sampling. In a typical batches-of-data setting this usually
| corresponds to the number of examples in the entire dataset.
| Defaults to `1.0` which corresponds to no scaling.
|
| session : tensorflow.Session, optional
| Session object which knows about the external part of the graph
| (which defines `Cost`, and possibly batches).
| Used internally to evaluate (burn-in/sample) the sampler.
|
| dtype : tensorflow.DType, optional
| Type of elements of `tensorflow.Tensor` objects used in this sampler.
| Defaults to `tensorflow.float64`.
|
| seed : int, optional
| Random seed to use.
| Defaults to `None`.
|
| See Also
| ----------
| pysgmcmc.sampling.BurnInMCMCSampler:
| Base class for `SGHMCSampler` that specifies how actual sampling
| is performed (using iterator protocol, e.g. `next(sampler)`).
|
| ----------------------------------------------------------------------
| Methods inherited from pysgmcmc.samplers.base_classes.BurnInMCMCSampler:
|
| __next__(self, feed_dict=None)
| Perform a sampler step:
| Compute and return the next sample and next cost values
| for this sampler.
|
| While `self.is_burning_in` returns `True`
| (while the sampler has not yet performed `self.burn_in_steps`
| steps) this will also adapt the samplers mass matrix in a
| sampler-specific way to improve performance.
|
| Returns
| -------
| sample: list of numpy.ndarray objects
| Sampled values are a `numpy.ndarray` for each target parameter.
|
| cost: numpy.ndarray (1,)
| Current cost value of the last evaluated target parameter values.
|
| ----------------------------------------------------------------------
| Data descriptors inherited from pysgmcmc.samplers.base_classes.BurnInMCMCSampler:
|
| is_burning_in
| Check if this sampler is still in burn-in phase.
| Used during graph construction to insert conditionals into the
| graph that will make the sampler skip all burn-in operations
| after the burn-in phase is over.
|
| Returns
| -------
| is_burning_in: boolean
| `True` if `self.n_iterations <= self.burn_in_steps`, otherwise `False`.
|
| ----------------------------------------------------------------------
| Data and other attributes inherited from pysgmcmc.samplers.base_classes.BurnInMCMCSampler:
|
| __metaclass__ = <class 'abc.ABCMeta'>
| Metaclass for defining Abstract Base Classes (ABCs).
|
| Use this metaclass to create an ABC. An ABC can be subclassed
| directly, and then acts as a mix-in class. You can also register
| unrelated concrete classes (even built-in classes) and unrelated
| ABCs as 'virtual subclasses' -- these and their descendants will
| be considered subclasses of the registering ABC by the built-in
| issubclass() function, but the registering ABC won't show up in
| their MRO (Method Resolution Order) nor will method
| implementations defined by the registering ABC be callable (not
| even via super()).
|
| ----------------------------------------------------------------------
| Methods inherited from pysgmcmc.samplers.base_classes.MCMCSampler:
|
| __iter__(self)
| Allows using samplers as iterators.
|
| Examples
| ----------
| Extract the first three thousand samples (with costs) from a sampler:
|
| >>> import tensorflow as tf
| >>> import numpy as np
| >>> from itertools import islice
| >>> from pysgmcmc.samplers.sghmc import SGHMCSampler
| >>> session = tf.Session()
| >>> x = tf.Variable(1.0)
| >>> dist = tf.contrib.distributions.Normal(loc=0., scale=1.)
| >>> n_burn_in, n_samples = 1000, 2000
| >>> sampler = SGHMCSampler(params=[x], burn_in_steps=n_burn_in, cost_fun=lambda x: -dist.log_prob(x), session=session, dtype=tf.float32)
| >>> session.run(tf.global_variables_initializer())
| >>> burn_in_samples = list(islice(sampler, n_burn_in)) # perform all burn_in steps
| >>> samples = list(islice(sampler, n_samples))
| >>> len(burn_in_samples), len(samples)
| (1000, 2000)
| >>> session.close()
| >>> tf.reset_default_graph() # to avoid polluting test environment
|
| ----------------------------------------------------------------------
| Data descriptors inherited from pysgmcmc.samplers.base_classes.MCMCSampler:
|
| __dict__
| dictionary for instance variables (if defined)
|
| __weakref__
| list of weak references to the object (if defined)
class SGLDSampler(pysgmcmc.samplers.base_classes.BurnInMCMCSampler)
| Stochastic Gradient Langevin Dynamics Sampler that uses a burn-in
| procedure to adapt its own hyperparameters during the initial stages
| of sampling.
|
| See [1] for more details on this burn-in procedure.
| See [2] for more details on Stochastic Gradient Langevin Dynamics.
|
| [1] J. T. Springenberg, A. Klein, S. Falkner, F. Hutter
| In Advances in Neural Information Processing Systems 29 (2016).
|
| `Bayesian Optimization with Robust Bayesian Neural Networks. <http://aad.informatik.uni-freiburg.de/papers/16-NIPS-BOHamiANN.pdf>`_
|
| [2] M.Welling, Y. W. Teh
| In International Conference on Machine Learning (ICML) 28 (2011).
|
| `Bayesian Learning via Stochastic Gradient Langevin Dynamics. <https://www.ics.uci.edu/~welling/publications/papers/stoclangevin_v6.pdf>`_
|
| Method resolution order:
| SGLDSampler
| pysgmcmc.samplers.base_classes.BurnInMCMCSampler
| pysgmcmc.samplers.base_classes.MCMCSampler
| builtins.object
|
| Methods defined here:
|
| __init__(self, params, cost_fun, batch_generator=None, stepsize_schedule=<pysgmcmc.stepsize_schedules.ConstantStepsizeSchedule object at 0x7f0950845518>, burn_in_steps=3000, A=1.0, scale_grad=1.0, session=None, dtype=tf.float64, seed=None)
| Initialize the sampler parameters and set up a tensorflow.Graph
| for later queries.
|
| Parameters
| ----------
| params : list of tensorflow.Variable objects
| Target parameters for which we want to sample new values.
|
| cost_fun : callable
| Function that takes `params` as input and returns a
| 1-d `tensorflow.Tensor` that contains the cost-value.
| Frequently denoted with `U` in literature.
|
| batch_generator : BatchGenerator, optional
| Iterable which returns dictionaries to feed into
| tensorflow.Session.run() calls to evaluate the cost function.
| Defaults to `None` which indicates that no batches shall be fed.
|
| stepsize_schedule : pysgmcmc.stepsize_schedules.StepsizeSchedule
| Iterator class that produces a stream of stepsize values that
| we can use in our samplers.
| See also: `pysgmcmc.stepsize_schedules`
|
| burn_in_steps: int, optional
| Number of burn-in steps to perform. In each burn-in step, this
| sampler will adapt its own internal parameters to decrease its error.
| Defaults to `3000`.
|
| For reference see:
| `Bayesian Optimization with Robust Bayesian Neural Networks. <http://aad.informatik.uni-freiburg.de/papers/16-NIPS-BOHamiANN.pdf>`_
|
| A : float, optional
| TODO Doku
| Defaults to `1.0`.
|
| scale_grad : float, optional
| Value that is used to scale the magnitude of the noise used
| during sampling. In a typical batches-of-data setting this usually
| corresponds to the number of examples in the entire dataset.
|
| session : tensorflow.Session, optional
| Session object which knows about the external part of the graph
| (which defines `Cost`, and possibly batches).
| Used internally to evaluate (burn-in/sample) the sampler.
|
| dtype : tensorflow.DType, optional
| Type of elements of `tensorflow.Tensor` objects used in this sampler.
| Defaults to `tensorflow.float64`.
|
| seed : int, optional
| Random seed to use.
| Defaults to `None`.
|
| See Also
| ----------
| tensorflow_mcmc.sampling.mcmc_base_classes.BurnInMCMCSampler:
| Base class for `SGLDSampler` that specifies how actual sampling
| is performed (using iterator protocol, e.g. `next(sampler)`).
|
| ----------------------------------------------------------------------
| Methods inherited from pysgmcmc.samplers.base_classes.BurnInMCMCSampler:
|
| __next__(self, feed_dict=None)
| Perform a sampler step:
| Compute and return the next sample and next cost values
| for this sampler.
|
| While `self.is_burning_in` returns `True`
| (while the sampler has not yet performed `self.burn_in_steps`
| steps) this will also adapt the samplers mass matrix in a
| sampler-specific way to improve performance.
|
| Returns
| -------
| sample: list of numpy.ndarray objects
| Sampled values are a `numpy.ndarray` for each target parameter.
|
| cost: numpy.ndarray (1,)
| Current cost value of the last evaluated target parameter values.
|
| ----------------------------------------------------------------------
| Data descriptors inherited from pysgmcmc.samplers.base_classes.BurnInMCMCSampler:
|
| is_burning_in
| Check if this sampler is still in burn-in phase.
| Used during graph construction to insert conditionals into the
| graph that will make the sampler skip all burn-in operations
| after the burn-in phase is over.
|
| Returns
| -------
| is_burning_in: boolean
| `True` if `self.n_iterations <= self.burn_in_steps`, otherwise `False`.
|
| ----------------------------------------------------------------------
| Data and other attributes inherited from pysgmcmc.samplers.base_classes.BurnInMCMCSampler:
|
| __metaclass__ = <class 'abc.ABCMeta'>
| Metaclass for defining Abstract Base Classes (ABCs).
|
| Use this metaclass to create an ABC. An ABC can be subclassed
| directly, and then acts as a mix-in class. You can also register
| unrelated concrete classes (even built-in classes) and unrelated
| ABCs as 'virtual subclasses' -- these and their descendants will
| be considered subclasses of the registering ABC by the built-in
| issubclass() function, but the registering ABC won't show up in
| their MRO (Method Resolution Order) nor will method
| implementations defined by the registering ABC be callable (not
| even via super()).
|
| ----------------------------------------------------------------------
| Methods inherited from pysgmcmc.samplers.base_classes.MCMCSampler:
|
| __iter__(self)
| Allows using samplers as iterators.
|
| Examples
| ----------
| Extract the first three thousand samples (with costs) from a sampler:
|
| >>> import tensorflow as tf
| >>> import numpy as np
| >>> from itertools import islice
| >>> from pysgmcmc.samplers.sghmc import SGHMCSampler
| >>> session = tf.Session()
| >>> x = tf.Variable(1.0)
| >>> dist = tf.contrib.distributions.Normal(loc=0., scale=1.)
| >>> n_burn_in, n_samples = 1000, 2000
| >>> sampler = SGHMCSampler(params=[x], burn_in_steps=n_burn_in, cost_fun=lambda x: -dist.log_prob(x), session=session, dtype=tf.float32)
| >>> session.run(tf.global_variables_initializer())
| >>> burn_in_samples = list(islice(sampler, n_burn_in)) # perform all burn_in steps
| >>> samples = list(islice(sampler, n_samples))
| >>> len(burn_in_samples), len(samples)
| (1000, 2000)
| >>> session.close()
| >>> tf.reset_default_graph() # to avoid polluting test environment
|
| ----------------------------------------------------------------------
| Data descriptors inherited from pysgmcmc.samplers.base_classes.MCMCSampler:
|
| __dict__
| dictionary for instance variables (if defined)
|
| __weakref__
| list of weak references to the object (if defined)
class SVGDSampler(pysgmcmc.samplers.base_classes.MCMCSampler)
| Stein Variational Gradient Descent Sampler.
|
| See [1] for more details on stein variational gradient descent.
|
|
| [1] Q. Liu, D. Wang
| In Advances in Neural Information Processing Systems 29 (2016).
|
| `Stein Variational Gradient Descent: A General Purpose Bayesian Inference Algorithm. <https://arxiv.org/pdf/1608.04471>`_
|
| Method resolution order:
| SVGDSampler
| pysgmcmc.samplers.base_classes.MCMCSampler
| builtins.object
|
| Methods defined here:
|
| __init__(self, particles, cost_fun, batch_generator=None, stepsize_schedule=<pysgmcmc.stepsize_schedules.ConstantStepsizeSchedule object at 0x7f09508457f0>, alpha=0.9, fudge_factor=1e-06, session=None, dtype=tf.float64, seed=None)
| Initialize the sampler parameters and set up a tensorflow.Graph
| for later queries.
|
| Parameters
| ----------
| particles : List[tensorflow.Variable]
| List of particles each representing a (different) guess of the
| target parameters of this sampler.
|
| cost_fun : callable
| Function that takes `params` of *one* particle as input and
| returns a 1-d `tensorflow.Tensor` that contains the cost-value.
| Frequently denoted with `U` in literature.
|
| batch_generator : iterable, optional
| Iterable which returns dictionaries to feed into
| tensorflow.Session.run() calls to evaluate the cost function.
| Defaults to `None` which indicates that no batches shall be fed.
|
| stepsize_schedule : pysgmcmc.stepsize_schedules.StepsizeSchedule
| Iterator class that produces a stream of stepsize values that
| we can use in our samplers.
| See also: `pysgmcmc.stepsize_schedules`
|
| alpha : float, optional
| TODO DOKU
| Defaults to `0.9`.
|
| fudge_factor : float, optional
| TODO DOKU
| Defaults to `1e-6`.
|
| session : tensorflow.Session, optional
| Session object which knows about the external part of the graph
| (which defines `Cost`, and possibly batches).
| Used internally to evaluate (burn-in/sample) the sampler.
|
| dtype : tensorflow.DType, optional
| Type of elements of `tensorflow.Tensor` objects used in this sampler.
| Defaults to `tensorflow.float64`.
|
| seed : int, optional
| Random seed to use.
| Defaults to `None`.
|
| See Also
| ----------
| pysgmcmc.sampling.MCMCSampler:
| Base class for `SteinVariationalGradientDescentSampler` that
| specifies how actual sampling is performed (using iterator protocol,
| e.g. `next(sampler)`).
|
| svgd_kernel(self, particles)
| Calculate a kernel matrix with corresponding derivatives
| for the given `particles`.
| TODO: DOKU ON KERNEL TRICK
|
| Parameters
| ----------
| particles : TODO
|
| Returns
| ----------
| kernel_matrix : tf.Tensor
| TODO
|
| kernel_gradients : tf.Tensor
| TODO
|
| ----------------------------------------------------------------------
| Methods inherited from pysgmcmc.samplers.base_classes.MCMCSampler:
|
| __iter__(self)
| Allows using samplers as iterators.
|
| Examples
| ----------
| Extract the first three thousand samples (with costs) from a sampler:
|
| >>> import tensorflow as tf
| >>> import numpy as np
| >>> from itertools import islice
| >>> from pysgmcmc.samplers.sghmc import SGHMCSampler
| >>> session = tf.Session()
| >>> x = tf.Variable(1.0)
| >>> dist = tf.contrib.distributions.Normal(loc=0., scale=1.)
| >>> n_burn_in, n_samples = 1000, 2000
| >>> sampler = SGHMCSampler(params=[x], burn_in_steps=n_burn_in, cost_fun=lambda x: -dist.log_prob(x), session=session, dtype=tf.float32)
| >>> session.run(tf.global_variables_initializer())
| >>> burn_in_samples = list(islice(sampler, n_burn_in)) # perform all burn_in steps
| >>> samples = list(islice(sampler, n_samples))
| >>> len(burn_in_samples), len(samples)
| (1000, 2000)
| >>> session.close()
| >>> tf.reset_default_graph() # to avoid polluting test environment
|
| __next__(self, feed_dict=None)
| Compute and return the next sample and
| next cost values for this sampler.
|
| Returns
| --------
| sample: list of numpy.ndarray objects
| Sampled values are a `numpy.ndarray` for each target parameter.
|
| cost: numpy.ndarray (1,)
| Current cost value of the last evaluated target parameter values.
|
| Examples
| --------
| Extract the next sample (with costs) from a sampler:
|
| >>> import tensorflow as tf
| >>> import numpy as np
| >>> from itertools import islice
| >>> from pysgmcmc.samplers.sghmc import SGHMCSampler
| >>> session = tf.Session()
| >>> x = tf.Variable(1.0)
| >>> dist = tf.contrib.distributions.Normal(loc=0., scale=1.)
| >>> n_burn_in = 1000
| >>> sampler = SGHMCSampler(params=[x], burn_in_steps=n_burn_in, cost_fun=lambda x:-dist.log_prob(x), session=session, dtype=tf.float32)
| >>> session.run(tf.global_variables_initializer())
| >>> sample, cost = next(sampler)
| >>> session.close()
| >>> tf.reset_default_graph() # to avoid polluting test environment
|
| ----------------------------------------------------------------------
| Data descriptors inherited from pysgmcmc.samplers.base_classes.MCMCSampler:
|
| __dict__
| dictionary for instance variables (if defined)
|
| __weakref__
| list of weak references to the object (if defined)
|
| ----------------------------------------------------------------------
| Data and other attributes inherited from pysgmcmc.samplers.base_classes.MCMCSampler:
|
| __metaclass__ = <class 'abc.ABCMeta'>
| Metaclass for defining Abstract Base Classes (ABCs).
|
| Use this metaclass to create an ABC. An ABC can be subclassed
| directly, and then acts as a mix-in class. You can also register
| unrelated concrete classes (even built-in classes) and unrelated
| ABCs as 'virtual subclasses' -- these and their descendants will
| be considered subclasses of the registering ABC by the built-in
| issubclass() function, but the registering ABC won't show up in
| their MRO (Method Resolution Order) nor will method
| implementations defined by the registering ABC be callable (not
| even via super()).
DATA
__all__ = ['SGHMCSampler', 'RelativisticSGHMCSampler', 'SGLDSampler', ...
FILE
/mhome/freidanm/repos/pysgmcmc/pysgmcmc/samplers/__init__.py
Sampler hyperparameters¶
To get a clearer picture of all possible design choices when instantiating any of our samplers, consider our docstrings:
In [6]:
help(pg.samplers.SGHMCSampler)
Help on class SGHMCSampler in module pysgmcmc.samplers.sghmc:
class SGHMCSampler(pysgmcmc.samplers.base_classes.BurnInMCMCSampler)
| Stochastic Gradient Hamiltonian Monte-Carlo Sampler that uses a burn-in
| procedure to adapt its own hyperparameters during the initial stages
| of sampling.
|
| See [1] for more details on this burn-in procedure.
|
| See [2] for more details on Stochastic Gradient Hamiltonian Monte-Carlo.
|
| [1] J. T. Springenberg, A. Klein, S. Falkner, F. Hutter
| In Advances in Neural Information Processing Systems 29 (2016).
|
|
| `Bayesian Optimization with Robust Bayesian Neural Networks. <http://aad.informatik.uni-freiburg.de/papers/16-NIPS-BOHamiANN.pdf>`_
|
|
| [2] T. Chen, E. B. Fox, C. Guestrin
| In Proceedings of Machine Learning Research 32 (2014).
|
| `Stochastic Gradient Hamiltonian Monte Carlo <https://arxiv.org/pdf/1402.4102.pdf>`_
|
| Method resolution order:
| SGHMCSampler
| pysgmcmc.samplers.base_classes.BurnInMCMCSampler
| pysgmcmc.samplers.base_classes.MCMCSampler
| builtins.object
|
| Methods defined here:
|
| __init__(self, params, cost_fun, batch_generator=None, stepsize_schedule=<pysgmcmc.stepsize_schedules.ConstantStepsizeSchedule object at 0x7f09508b53c8>, burn_in_steps=3000, mdecay=0.05, scale_grad=1.0, session=None, dtype=tf.float64, seed=None)
| Initialize the sampler parameters and set up a tensorflow.Graph
| for later queries.
|
| Parameters
| ----------
| params : list of tensorflow.Variable objects
| Target parameters for which we want to sample new values.
|
| cost_fun : callable
| Function that takes `params` as input and returns a
| 1-d `tensorflow.Tensor` that contains the cost-value.
| Frequently denoted with `U` in literature.
|
| batch_generator : iterable, optional
| Iterable which returns dictionaries to feed into
| tensorflow.Session.run() calls to evaluate the cost function.
| Defaults to `None` which indicates that no batches shall be fed.
|
| stepsize_schedule : pysgmcmc.stepsize_schedules.StepsizeSchedule
| Iterator class that produces a stream of stepsize values that
| we can use in our samplers.
| See also: `pysgmcmc.stepsize_schedules`
|
| burn_in_steps : int, optional
| Number of burn-in steps to perform. In each burn-in step, this
| sampler will adapt its own internal parameters to decrease its error.
| Defaults to `3000`.
|
| For reference see:
| `Bayesian Optimization with Robust Bayesian Neural Networks. <http://aad.informatik.uni-freiburg.de/papers/16-NIPS-BOHamiANN.pdf>`_
|
| mdecay : float, optional
| (Constant) momentum decay per time-step.
| Defaults to `0.05`.
|
| For reference see:
| `Bayesian Optimization with Robust Bayesian Neural Networks. <http://aad.informatik.uni-freiburg.de/papers/16-NIPS-BOHamiANN.pdf>`_
|
| scale_grad : float, optional
| Value that is used to scale the magnitude of the noise used
| during sampling. In a typical batches-of-data setting this usually
| corresponds to the number of examples in the entire dataset.
| Defaults to `1.0` which corresponds to no scaling.
|
| session : tensorflow.Session, optional
| Session object which knows about the external part of the graph
| (which defines `Cost`, and possibly batches).
| Used internally to evaluate (burn-in/sample) the sampler.
|
| dtype : tensorflow.DType, optional
| Type of elements of `tensorflow.Tensor` objects used in this sampler.
| Defaults to `tensorflow.float64`.
|
| seed : int, optional
| Random seed to use.
| Defaults to `None`.
|
| See Also
| ----------
| pysgmcmc.sampling.BurnInMCMCSampler:
| Base class for `SGHMCSampler` that specifies how actual sampling
| is performed (using iterator protocol, e.g. `next(sampler)`).
|
| ----------------------------------------------------------------------
| Methods inherited from pysgmcmc.samplers.base_classes.BurnInMCMCSampler:
|
| __next__(self, feed_dict=None)
| Perform a sampler step:
| Compute and return the next sample and next cost values
| for this sampler.
|
| While `self.is_burning_in` returns `True`
| (while the sampler has not yet performed `self.burn_in_steps`
| steps) this will also adapt the samplers mass matrix in a
| sampler-specific way to improve performance.
|
| Returns
| -------
| sample: list of numpy.ndarray objects
| Sampled values are a `numpy.ndarray` for each target parameter.
|
| cost: numpy.ndarray (1,)
| Current cost value of the last evaluated target parameter values.
|
| ----------------------------------------------------------------------
| Data descriptors inherited from pysgmcmc.samplers.base_classes.BurnInMCMCSampler:
|
| is_burning_in
| Check if this sampler is still in burn-in phase.
| Used during graph construction to insert conditionals into the
| graph that will make the sampler skip all burn-in operations
| after the burn-in phase is over.
|
| Returns
| -------
| is_burning_in: boolean
| `True` if `self.n_iterations <= self.burn_in_steps`, otherwise `False`.
|
| ----------------------------------------------------------------------
| Data and other attributes inherited from pysgmcmc.samplers.base_classes.BurnInMCMCSampler:
|
| __metaclass__ = <class 'abc.ABCMeta'>
| Metaclass for defining Abstract Base Classes (ABCs).
|
| Use this metaclass to create an ABC. An ABC can be subclassed
| directly, and then acts as a mix-in class. You can also register
| unrelated concrete classes (even built-in classes) and unrelated
| ABCs as 'virtual subclasses' -- these and their descendants will
| be considered subclasses of the registering ABC by the built-in
| issubclass() function, but the registering ABC won't show up in
| their MRO (Method Resolution Order) nor will method
| implementations defined by the registering ABC be callable (not
| even via super()).
|
| ----------------------------------------------------------------------
| Methods inherited from pysgmcmc.samplers.base_classes.MCMCSampler:
|
| __iter__(self)
| Allows using samplers as iterators.
|
| Examples
| ----------
| Extract the first three thousand samples (with costs) from a sampler:
|
| >>> import tensorflow as tf
| >>> import numpy as np
| >>> from itertools import islice
| >>> from pysgmcmc.samplers.sghmc import SGHMCSampler
| >>> session = tf.Session()
| >>> x = tf.Variable(1.0)
| >>> dist = tf.contrib.distributions.Normal(loc=0., scale=1.)
| >>> n_burn_in, n_samples = 1000, 2000
| >>> sampler = SGHMCSampler(params=[x], burn_in_steps=n_burn_in, cost_fun=lambda x: -dist.log_prob(x), session=session, dtype=tf.float32)
| >>> session.run(tf.global_variables_initializer())
| >>> burn_in_samples = list(islice(sampler, n_burn_in)) # perform all burn_in steps
| >>> samples = list(islice(sampler, n_samples))
| >>> len(burn_in_samples), len(samples)
| (1000, 2000)
| >>> session.close()
| >>> tf.reset_default_graph() # to avoid polluting test environment
|
| ----------------------------------------------------------------------
| Data descriptors inherited from pysgmcmc.samplers.base_classes.MCMCSampler:
|
| __dict__
| dictionary for instance variables (if defined)
|
| __weakref__
| list of weak references to the object (if defined)
2. Extracting samples¶
Extracting the next sample (with corresponding costs) from any of our samplers always simply amounts to:
In [7]:
sample, cost = next(sampler)
sample, cost
Out[7]:
([-0.0037382236, 0.0019394364], -50.0)
This interface allows us to extract samples in different contexts:
- extract a chain of n subsequent samples
- sample until an external event occurs / an external condition becomes
true
In [8]:
# 1. extract a chain of n subsequent samples
samples, n = [], 1000
for _ in range(n):
sample, _ = next(sampler)
samples.append(sample)
# shorthand for 1., using itertools.islice
import itertools
samples = [sample for sample, _ in itertools.islice(sampler, n)]
# 2. sample until an external event occurs
# dummy event
def external_event():
return np.random.randint(0, 10) > 5
samples = []
while not external_event():
sample, _ = next(sampler)
samples.append(sample)
samples
Out[8]:
[]
This interface also allows us to use any of our samplers in (infinite) for-loops.
But be warned: such a for-loop will not terminate unless you explicitly break out of it:
In [9]:
samples, i = [], 0
for sample, cost in sampler:
if i > 10:
break # we need to explicitly *break* out of the loop
i += 1
samples.append(sample)
3. Analyzing chains/traces of samples¶
To analyze the results of a sampler run, pysgmcmc provides facilities to
transform the results obtained by our samplers into pymc3.MultiTrace
objects. Then we can use the (well-established) pymc3 machinery to
compute diagnostics for our samples:
In [21]:
import pymc3
from pysgmcmc.stepsize_schedules import ConstantStepsizeSchedule
from pysgmcmc.samplers.relativistic_sghmc import RelativisticSGHMCSampler
from pysgmcmc.diagnostics.sample_chains import PYSGMCMCTrace
from pysgmcmc.diagnostics.objective_functions import (
banana_log_likelihood,
to_negative_log_likelihood
)
banana_nll = to_negative_log_likelihood(banana_log_likelihood)
def get_sampler(session):
params = [
tf.Variable(0., dtype=tf.float32, name="x"),
tf.Variable(6., dtype=tf.float32, name="y")
]
sampler = RelativisticSGHMCSampler(
stepsize_schedule=ConstantStepsizeSchedule(0.1),
params=params,
cost_fun=banana_nll,
session=session,
dtype=tf.float32
)
session.run(tf.global_variables_initializer())
return sampler
n_chains = 2
n_samples_per_chain, keep_every = 10000, 10
single_traces = []
for chain_id in range(n_chains):
graph = tf.Graph()
with tf.Session(graph=graph) as session:
sampler = get_sampler(session=session)
session.run(tf.global_variables_initializer())
trace = PYSGMCMCTrace.from_sampler(
chain_id=chain_id,
sampler=sampler,
n_samples=n_samples_per_chain,
keep_every=keep_every,
)
single_traces.append(trace)
multitrace = pymc3.backends.base.MultiTrace(single_traces)
# Compute effective sample sizes (ess) using pymc3:
from pymc3.diagnostics import effective_n as effective_sample_sizes
ess = effective_sample_sizes(multitrace)
print("Effective Sample Sizes:")
print(ess)
Effective Sample Sizes:
{'x:0': 6.0, 'y:0': 3.0}
For convenience we also provide a shortcut function that can be used to directly compute a multitrace for one of our samplers:
In [27]:
help(pg.diagnostics.sample_chains.pymc3_multitrace)
Help on function pymc3_multitrace in module pysgmcmc.diagnostics.sample_chains:
pymc3_multitrace(get_sampler, n_chains=2, samples_per_chain=100, keep_every=10, parameter_names=None)
Extract chains from `sampler` and return them as `pymc3.MultiTrace` object.
Parameters
----------
get_sampler : callable
A callable that takes a `tensorflow.Session` object as input
and returns a (possibly already burnt-in) instance of a
`pysgmcmc.sampling.MCMCSampler` subclass.
parameter_names : List[String] or NoneType, optional
List of names for each target parameter of the sampler.
Defaults to `None`, which attempts to look the parameter names up
from the target parameters of the sampler returned by `get_sampler`.
Returns
----------
multitrace : pymc3.backends.base.MultiTrace
TODO: DOKU
Examples
----------
TODO ADD EXAMPLE
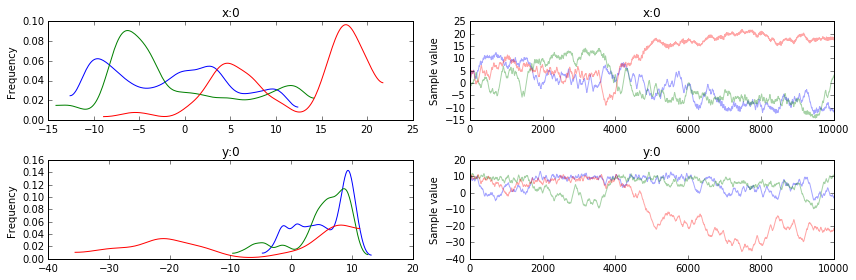
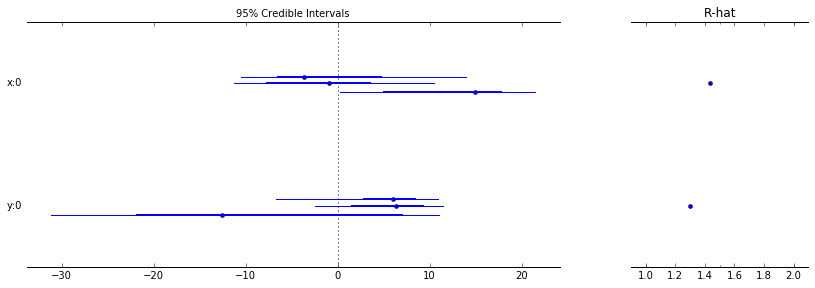
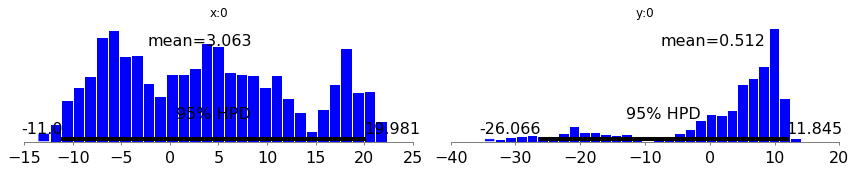
We can also rely on pymc3 plotting facilities to visualize several properties of our chains. Below we show some plots that demonstrate what is possible:
In [26]:
from pymc3.plots import (
traceplot, autocorrplot, forestplot, plot_posterior
)
from pysgmcmc.diagnostics.sample_chains import pymc3_multitrace
multitrace = pymc3_multitrace(get_sampler, n_chains=3, samples_per_chain=10000)
traceplot(multitrace)
autocorrplot(multitrace)
forestplot(multitrace)
plot_posterior(multitrace)
Out[26]:
array([<matplotlib.axes._subplots.AxesSubplot object at 0x7ff2fb47a198>,
<matplotlib.axes._subplots.AxesSubplot object at 0x7ff31c0d4518>], dtype=object)
4. PYSGMCMC - trained BNN¶
We also provide an implementation of a Bayesian Neural Network that is trained using our samplers.
The (tensorflow-) architecture of this BNN can be customized by the user and any of our sampling methods can be used to sample networks during training.
In [13]:
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from pysgmcmc.diagnostics.objective_functions import sinc
from pysgmcmc.models.bayesian_neural_network import BayesianNeuralNetwork
from pysgmcmc.sampling import Sampler
from pysgmcmc.stepsize_schedules import ConstantStepsizeSchedule
## Set up data ##
rng, n_datapoints = np.random.RandomState(np.random.randint(0, 10000)), 100
X_train = np.array([rng.uniform(0., 1., 1) for _ in range(n_datapoints)])
y_train = sinc(X_train)
X_test = np.linspace(0, 1, 100)[:, None]
y_test = sinc(X_test)
g = tf.Graph()
session = tf.InteractiveSession(graph=g)
with g.as_default():
model = BayesianNeuralNetwork(
session=session, batch_size=20, sampling_method=Sampler.SGHMC,
burn_in_steps=3000, n_iters=50000,
normalize_input=True, normalize_output=True,
stepsize_schedule=ConstantStepsizeSchedule(np.sqrt(1e-4)),
dtype=tf.float32,
# sampler arguments for SGHMC
mdecay=0.05,
)
model.train(X_train, y_train)
prediction_mean, prediction_variance = model.predict(X_test)
prediction_std = np.sqrt(prediction_variance)
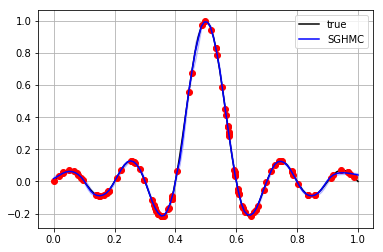
plt.grid()
plt.plot(X_test[:, 0], y_test, label="true", color="black")
plt.plot(X_train[:, 0], y_train, "ro")
plt.plot(X_test[:, 0], prediction_mean, label="SGHMC", color="blue")
plt.fill_between(X_test[:, 0], prediction_mean + prediction_std, prediction_mean - prediction_std, alpha=0.2, color="blue")
plt.legend()
plt.show()
print()